氏名から姓を取り出す
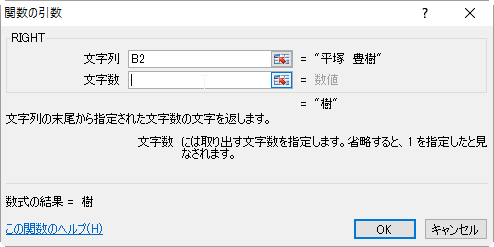
文字列の先頭から指定の文字数を取り出すにはLEFT関数を使います。
LEFT(文字列,文字数)
氏名の先頭から姓の文字数を指定すれば、姓を取り出すことができます。
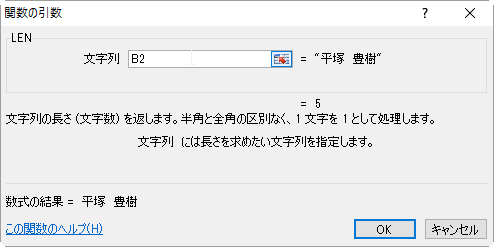
では、姓の文字数はどうすればわかるでしょうか。
上記のように姓と名の間のスペースの位置を調べれば姓の文字数を知ることができます
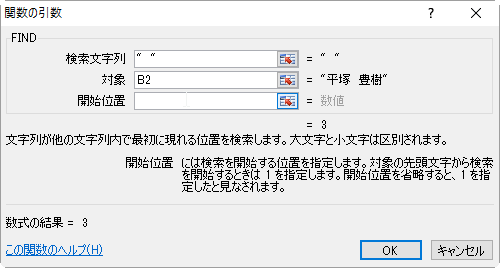
利用する関数は、FIND関数を使います。
FIND(検索文字列,対象,{開始位置})
このうち、開始位置は省略可能で、省略した時には1となります。
- まずC列とD列の間に2列追加しt、列見出しを「姓」、「名」とします。
- C2セルをポイントし、関数の挿入ボタンをおします。
- LEFT関数を探して〔OK〕ボタンを押します。
- 文字列にはB2セルを指定します。
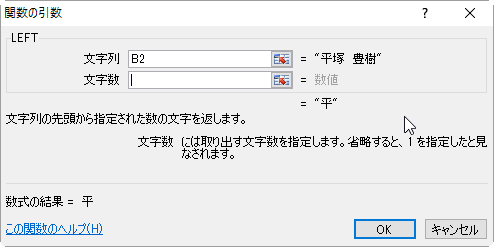
- 文字数のボックスをポイントします。
- 名前ボックスからFIND関数を探して、〔OK〕ボタンを押します。
- 〔検索文字列〕には「" "」(全角スペースを半角ダブルクォーテーションで挟みます)を入力し、
〔対象〕にはB2セルを指定します。開始位置は省略するか、1を入力します。
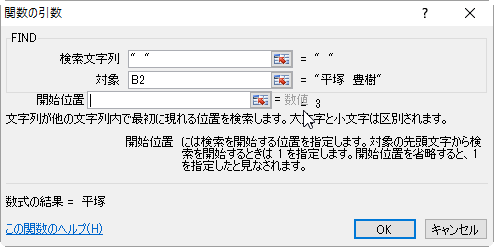
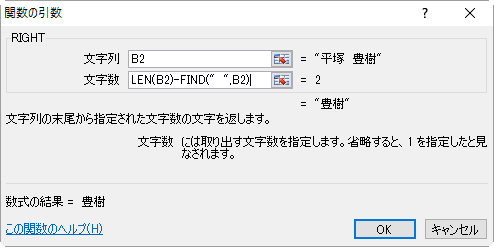
- 数式バーのLEFTあたりをクリックして、LEFTの引数ウィンドウを表示させます。
- このままだとFIND関数によりスペースの位置まで取り出してしまうので文字数を-1します。
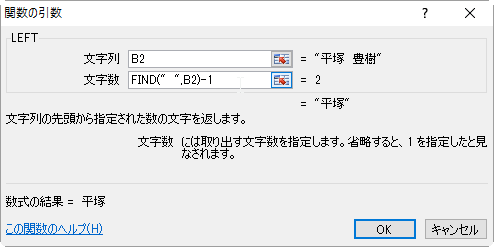
- 〔OK〕ボタンを押せば完成です。